
缓冲区管理器管理共享内存和持久性存储之间的数据传输,并且可能对DBMS的性能产生重大影响。 PostgreSQL缓冲区管理器非常高效。
在本章中,将介绍PostgreSQL缓冲区管理器。第一部分提供了概述,随后的部分描述了以下主题:
- Buffer manager structure
- Buffer manager locks
- How the buffer manager works
- Ring buffer
- Flushing of dirty pages
![Relations between buffer manager, storage, and backend processes.]()

Overview
本节介绍了有助于在后续各节中进行描述的关键概念。
Buffer Manager Structure
PostgreSQL缓冲区管理器包含一个缓冲区表,缓冲区描述符和缓冲池,这将在下一节中介绍。缓冲池层存储数据文件页面,例如表和索引,以及自由空间映射和可见性映射。缓冲池是一个数组,即每个插槽存储一个数据文件的一页。缓冲池阵列的索引称为buffer_id。
Buffer Tag
在PostgreSQL中,每一个数据文件的每一个页面分配了一个唯一的标签,即buffer tag。当缓冲区管理器收到请求时,PostgreSQL会使用目标页面的buffer_tag
buffer_tag包含三个值:其页面所属relation的RelFileNode和fork number,以及其页面的块编号。表,空闲空间映射和可见性映射的派生编号分别在0、1和2中定义。
例如,buffer_tag’{(16821,16384,37721),0,7}’ 表示这个页面位于relation中数据页面的第七块页面,relation的OID和派生编号分别为37721和0;在OID为16821的表空间下,其OID为16384的数据库中。
类似地,buffer_tag’{(16821,16384,37721),1,3}’ 表示这个页面位于relation中的freespace map页面第三个页面,relation的OID和派生编号分别为37721和1; 在OID为16821的表空间下,其OID为16384的数据库中。
How a Backend Process Reads Pages
本小节描述了后端进程如何从缓冲区管理器读取页面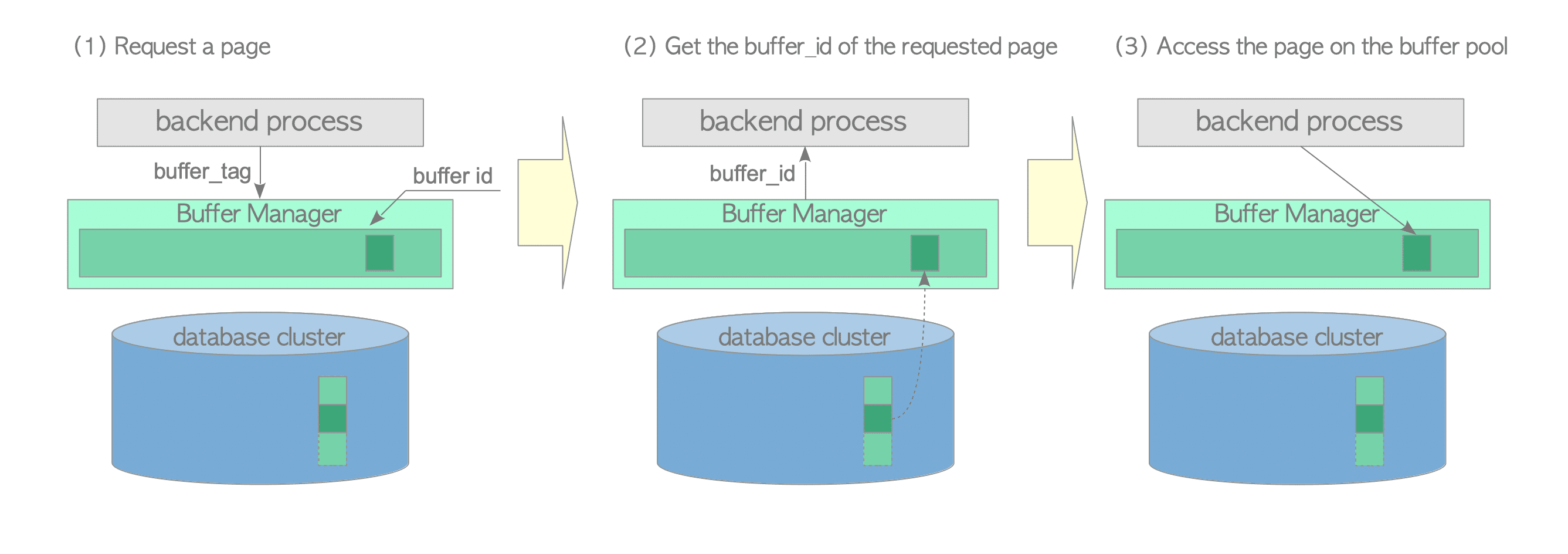
- 读取表或索引页时,后端进程会将包含页面的buffer_tag的请求发送到缓冲区管理器.
- 缓冲区管理器返回存储请求页面的插槽的buffer_ID。如果请求的页面未存储在缓冲池中,则缓冲管理器将页面从持久性存储加载到缓冲池插槽之一,然后返回buffer_ID的插槽
- 后端进程访问buffer_ID的插槽(以读取所需的页面
当后端进程修改缓冲池中的页面(例如,通过插入元组)时,尚未刷新到存储的修改后的页面称为脏页面。
Page Replacement Algorithm
当所有缓冲池插槽均被占用但未存储请求的页面时,缓冲管理器必须在缓冲池中选择一个页面,该页面将由请求的页面替换。通常,在计算机科学领域中,页面选择算法称为页面替换算法,而所选页面称为受害者页面
自计算机科学问世以来,一直在进行页面替换算法的研究。因此,先前已经提出了许多替换算法。从8.1版开始,PostgreSQL使用了clock-sweep,因为它比以前版本中使用的LRU算法更简单,更高效。
4.4节详细介绍了时钟扫描
Flushing Dirty Pages
脏页最终应刷新到存储中;但是,缓冲区管理器需要帮助才能执行此任务。在PostgreSQL中,两个后台进程(checkpointer和background writer)负责此任务。
第6节介绍了checkpointer和background writer
Direct I/O
PostgreSQL不支持direct I/O,尽管已经讨论过了。如果您想了解更多详细信息,请参考pgsql-ML和这篇文章。
Buffer Manager Structure
PostgreSQL缓冲区管理器包括三层,即缓冲区表(buffer table),缓冲区描述符(buffer descriptors)和缓冲池(buffer pool)
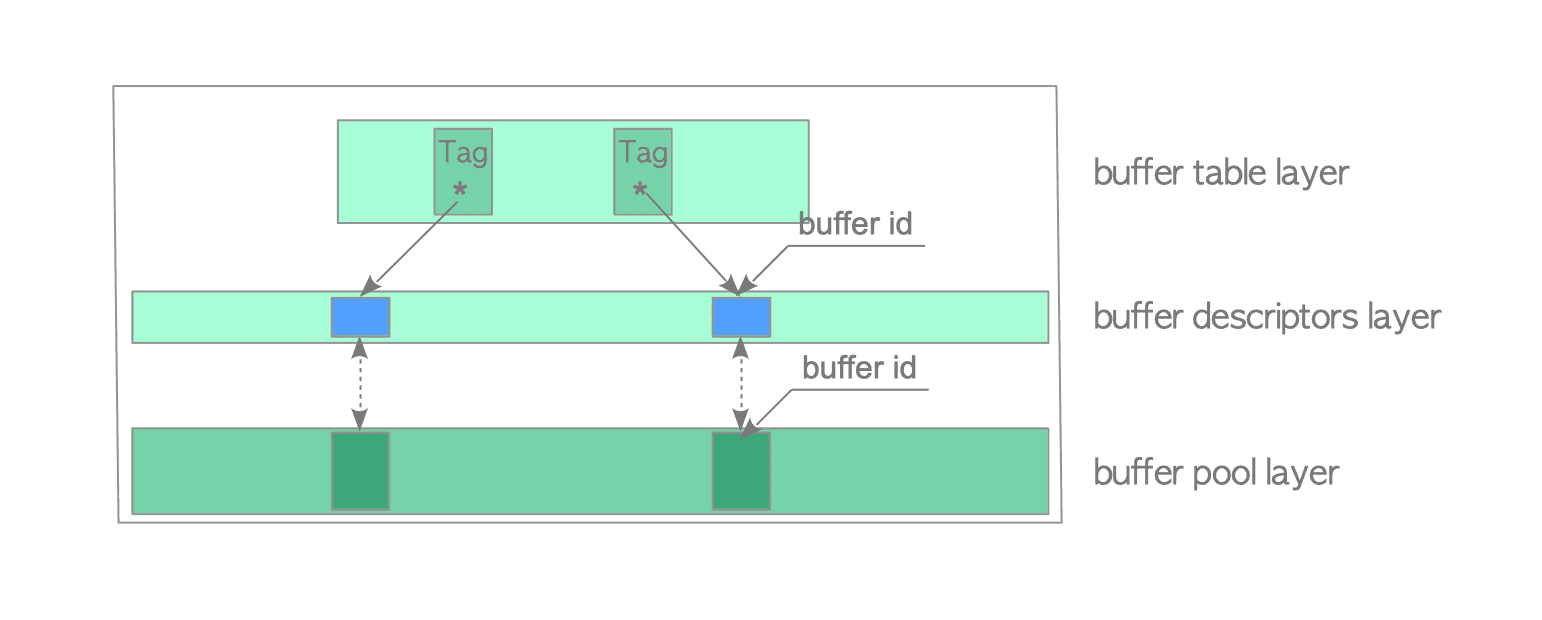
- 缓冲池是一个数组。每个插槽存储一个数据文件页面。阵列插槽的索引称为bufferids
缓冲区描述符层是缓冲区描述符的数组。每个描述符与缓冲池插槽一一对应,并在相应的插槽中保存存储页面的元数据。
Note
为方便起见,采用术语“缓冲区描述符层”,并且仅在本文档中使用。
缓冲区表是一个哈希表,用于存储存储页的buffer_tags与保存存储页各自元数据的描述符的buffer_id之间的关系。
这些层将在以下章节中详细介绍
Buffer Table
缓冲区表在逻辑上可以分为三个部分:哈希函数(a hash function),哈希存储桶插槽(hash bucket slots)和数据条目(data entries) (Fig. 8.4)
内置的哈希函数将buffer_tags映射到哈希存储桶插槽。由于哈希桶插槽的数量大于缓冲池插槽的数量,会发生冲突。因此,缓冲区表使用单独的链表链接方法来解决冲突。当数据条目(data entries)映射到相同的存储桶插槽(bucket slot)时,此方法将条目存储在相同的链表中,如图8.4所示。
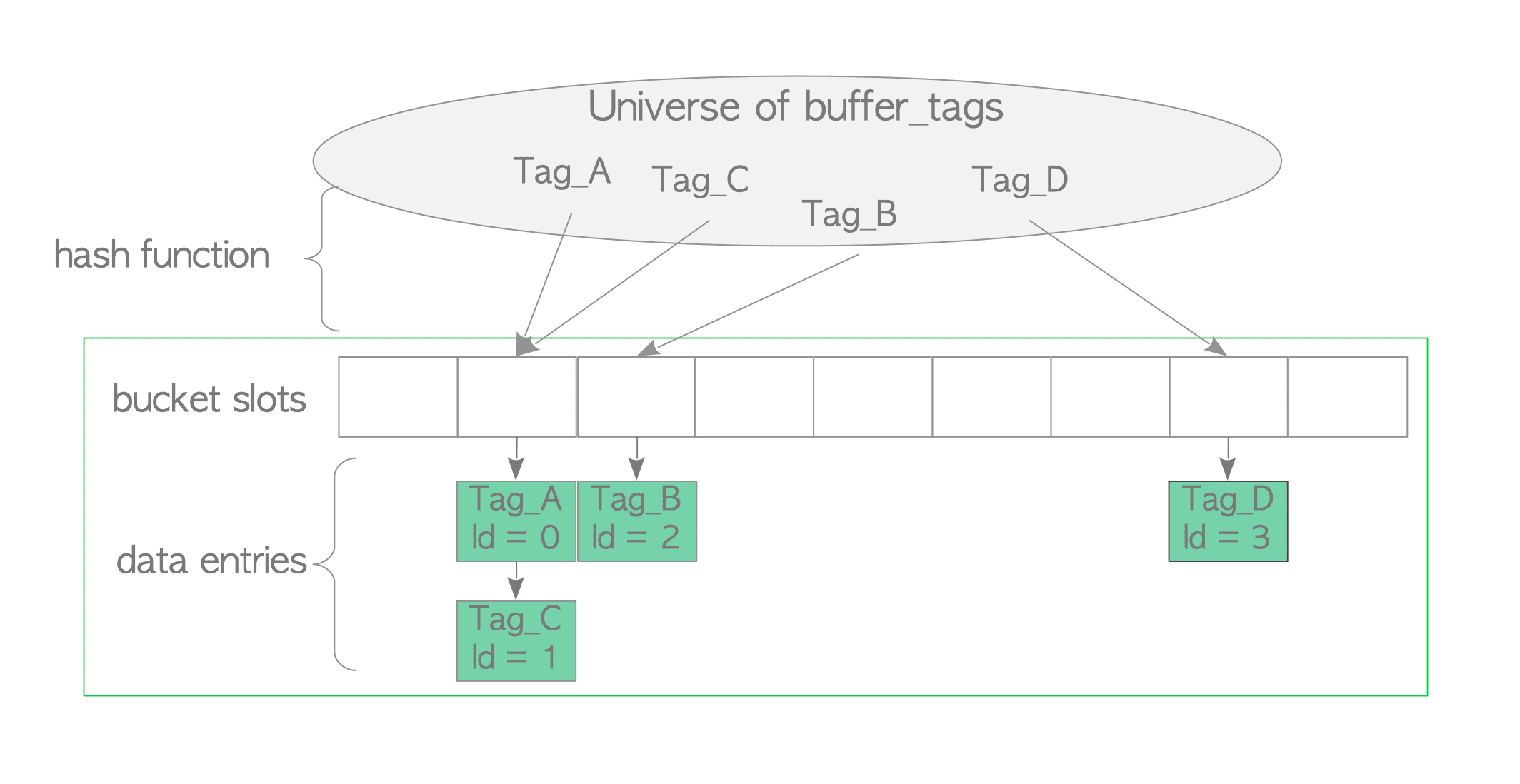
数据条目包含两个值:页面的buffer_tag和保存页面元数据的描述符的buffer_id。例如,数据条目’Tag_A,id = 1’表示具有buffer_id 1的缓冲区描述符存储带有Tag_A标签的页面的元数据。
Hash function
哈希函数是calc_bucket()和hash()的复合函数。以下是其作为伪函数的表示。
1 | |
NOTE
基本操作(查找,插入和删除数据条目)在此不作解释。这些是非常常见的操作,将在以下各节中进行说明。
Buffer Descriptor
缓冲区描述符的结构在本小节中描述,缓冲区描述符层在下一个小节中
缓冲区描述符将存储的页面的元数据保存在相应的缓冲池插槽中。缓冲区描述符结构由结构BufferDesc定义。虽然此结构有很多字段,但主要显示在以下字段中:
- tag 将存储页面的buffer_tag保存在相应的缓冲池插槽中(缓冲区标记在第1.2节中定义)
- buffer_id 标识描述符(等效于相应缓冲池插槽的buffer_id)
- refcount 保存当前正在访问关联的存储页面的PostgreSQL进程数。也称为引脚数(pin count)。 PostgreSQL进程访问存储的页面时,其引用计数必须增加1(refcount ++)。访问该页面后,其引用计数必须减少1(refcount—)。
当refcount为零时,即当前未访问关联的存储页面,则该页面被取消固定(unpinned);否则将其固定(pinned.)。 - usage_count 保存关联的存储页面自加载到相应的缓冲池插槽以来已被访问的次数。注意在页面替换算法(page replacement algorithm)中使用了usage_count (Section 4.4).
- context_lock和io_in_progress_lock是轻量级锁,用于控制对关联的存储页面的访问。这些字段在第3.2节中描述。
- flags 保存关联的存储页面的几种状态。主要状态如下:
- dirty bit 指示存储的页面是否脏.
- valid bit 指示是否可以读取或写入存储的页面(有效)。例如,如果该位有效,则相应的缓冲池插槽将存储一个页面,并且此描述符(有效位)将保存页面元数据;因此,可以读取或写入存储的页面。如果该位无效,则此描述符不包含任何元数据;这意味着无法读取或写入存储的页面,或者缓冲区管理器正在替换存储的页面。
- io_in_progress bit 指示缓冲区管理器是否正在从存储中读取/写入关联页面。换句话说,该位指示单个进程是否持有此描述符的
- freeNext 指向下一个描述符以生成空闲列表的指针,这将在下一个小节中进行描述。
NOTE
结构 BufferDesc 定义在 src/include/storage/buf_internals.h.
To simplify the following descriptions, three descriptor states are defined:
Empty: When the corresponding buffer pool slot does not store a page (i.e. refcount and usage_count are 0), the state of this descriptor is empty.
Pinned: When the corresponding buffer pool slot stores a page and any PostgreSQL processes are accessing the page (i.e. refcount and usage_count are greater than or equal to 1), the state of this buffer descriptor is pinned.
Unpinned: When the corresponding buffer pool slot stores a page but no PostgreSQL processes are accessing the page (i.e. usage_count is greater than or equal to 1, but refcount is 0), the state of this buffer descriptor is unpinned.
Each descriptor will have one of the above states. The descriptor state changes relative to particular conditions, which are described in the next subsection.
In the following figures, buffer descriptors’ states are represented by coloured boxes.
(white) Empty
(blue) Pinned
(aqua blue) Unpinned
In addition, a dirty page is denoted as ‘X’. For example, an unpinned dirty descriptor is represented by X .
Buffer Descriptors Layer
A collection of buffer descriptors forms an array. In this document, the array is referred to as the buffer descriptors layer.
When the PostgreSQL server starts, the state of all buffer descriptors is empty. In PostgreSQL, those descriptors comprise a linked list called freelist (Fig. 8.5).
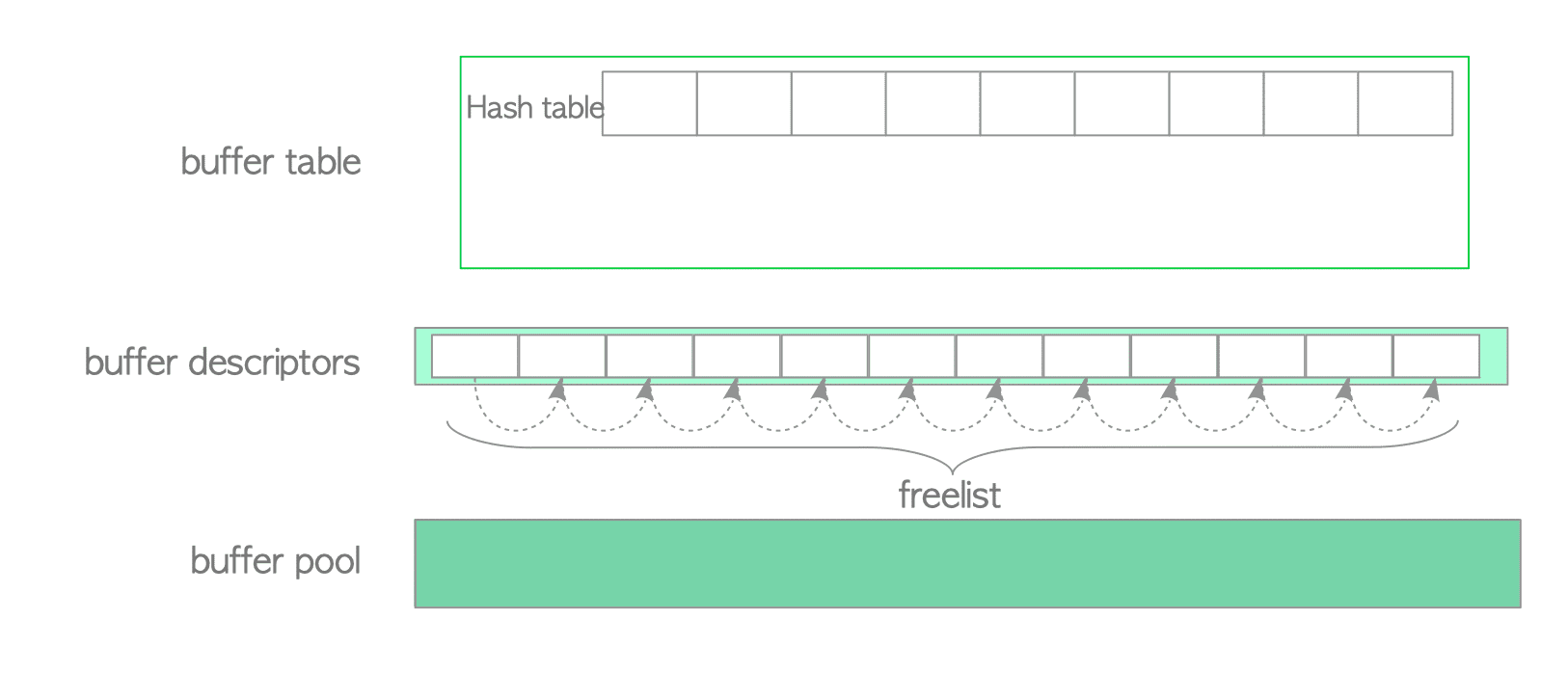
*NOTE
Please note that the freelist in PostgreSQL is completely different concept from the freelists in Oracle. PostgreSQL’s freelist is only linked list of empty buffer descriptors. In PostgreSQL freespace maps, which are described in Section 5.3.4, act as the same role of the freelists in Oracle.
Figure 8.6 shows that how the first page is loaded.
- Retrieve an empty descriptor from the top of the freelist, and pin it (i.e. increase its refcount and usage_count by 1).
- Insert the new entry, which holds the relation between the tag of the first page and the buffer_id of the retrieved descriptor, in the buffer table.
- Load the new page from storage to the corresponding buffer pool slot.
- Save the metadata of the new page to the retrieved descriptor.
The second and subsequent pages are loaded in a similar manner. Additional details are provided in Section 8.4.2.
Descriptors that have been retrieved from the freelist always hold page’s metadata. In other words, non-empty descriptors continue to be used do not return to the freelist. However, related descriptors are added to the freelist again and the descriptor state becomes ‘empty’ when one of the following occurs:
- Tables or indexes have been dropped.
- Databases have been dropped.
- Tables or indexes have been cleaned up using the VACUUM FULL command.
Why empty descriptors comprise the freelist?
The reason why the freelist be made is to get the first descriptor immediately. This is a usual practice for dynamic memory resource allocation. Refer to this description.
The buffer descriptors layer contains an unsigned 32-bit integer variable, i.e. nextVictimBuffer. This variable is used in the page replacement algorithm described in Section 8.4.4.
Buffer Pool
The buffer pool is a simple array that stores data file pages, such as tables and indexes. Indices of the buffer pool array are referred to as buffer_ids.
The buffer pool slot size is 8 KB, which is equal to the size of a page. Thus, each slot can store an entire page.
Buffer Manager Locks
The buffer manager uses many locks for many different purposes. This section describes the locks necessary for the explanations in the subsequent sections.
NOTE
Please note that the locks described in this section are parts of a synchronization mechanism for the buffer manager; they do not relate to any SQL statements and SQL options.
Buffer Table Locks
BufMappingLock protects the data integrity of the entire buffer table. It is a light-weight lock that can be used in both shared and exclusive modes. When searching an entry in the buffer table, a backend process holds a shared BufMappingLock. When inserting or deleting entries, a backend process holds an exclusive lock.
The BufMappingLock is split into partitions to reduce the contention in the buffer table (the default is 128 partitions). Each BufMappingLock partition guards the portion of the corresponding hash bucket slots.
Figure 8.7 shows a typical example of the effect of splitting BufMappingLock. Two backend processes can simultaneously hold respective BufMappingLock partitions in exclusive mode in order to insert new data entries. If the BufMappingLock is a single system-wide lock, both processes should wait for the processing of another process, depending on which started processing.
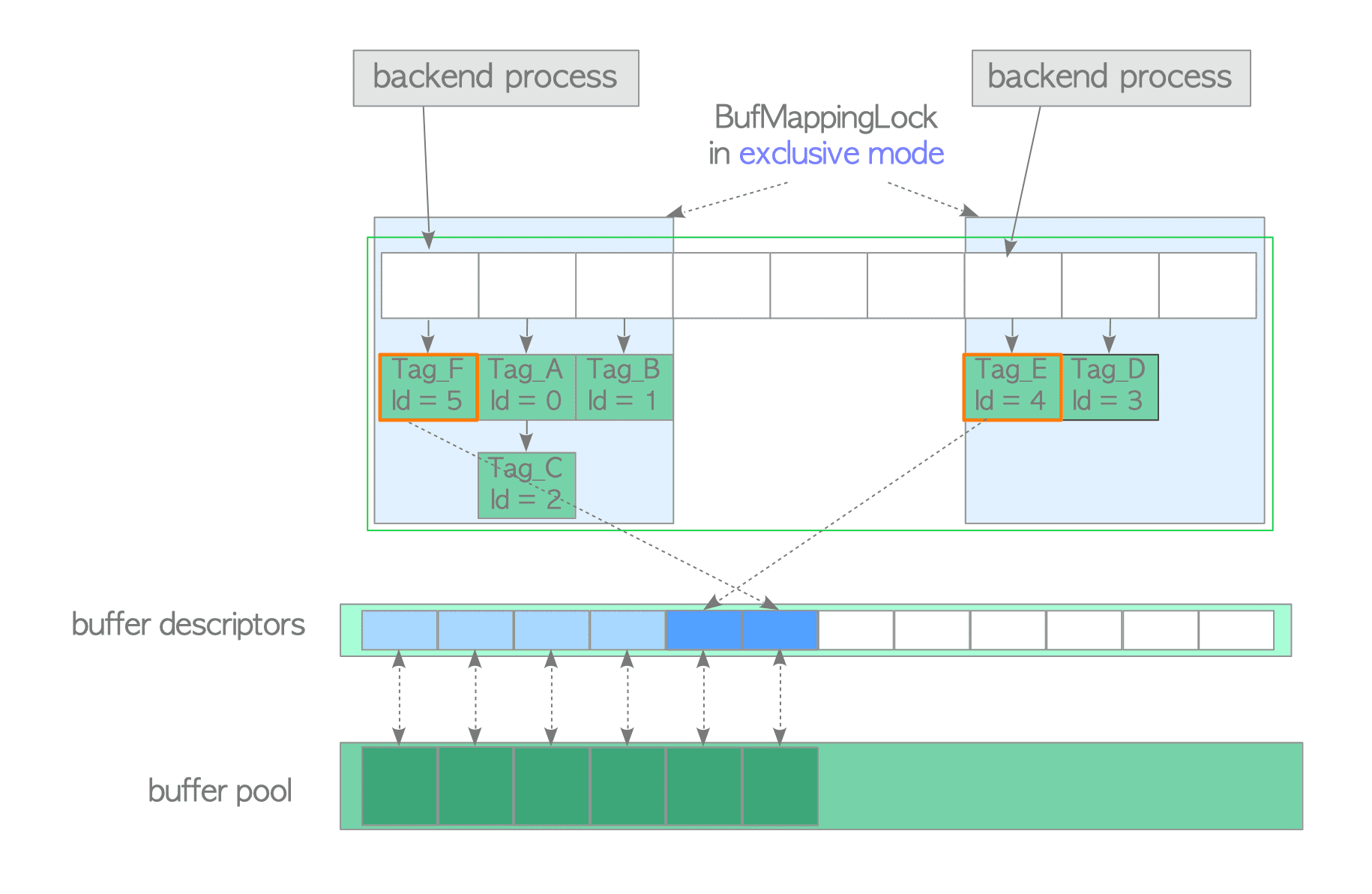
The buffer table requires many other locks. For example, the buffer table internally uses a spin lock to delete an entry. However, descriptions of these other locks are omitted because they are not required in this document.
NOTE
The BufMappingLock had been split into 16 separate locks by default until version 9.4.
Locks for Each Buffer Descriptor
Each buffer descriptor uses two light-weight locks, content_lock and io_in_progress_lock, to control access to the stored page in the corresponding buffer pool slot. When the values of own fields are checked or changed, a spinlock is used.
content_lock
The content_lock is a typical lock that enforces access limits. It can be used in shared and exclusive modes.
When reading a page, a backend process acquires a shared content_lock of the buffer descriptor that stores the page.
However, an exclusive content_lock is acquired when doing one of the following:
- Inserting rows (i.e. tuples) into the stored page or changing the t_xmin/t_xmax fields of tuples within the stored page (t_xmin and t_xmax are described in Section 5.2; simply, when deleting or updating rows, these fields of the associated tuples are changed).
- Removing tuples physically or compacting free space on the stored page (performed by vacuum processing and HOT, which are described in Chapters 6 and 7, respectively).
- Freezing tuples within the stored page (freezing is described in Section 5.10.1 and Section 6.3).
The official README file shows more details.
io_in_progress_lock
The io_in_progress lock is used to wait for I/O on a buffer to complete. When a PostgreSQL process loads/writes page data from/to storage, the process holds an exclusive io_in_progress lock of the corresponding descriptor while accessing the storage.
spinlock
When the flags or other fields (e.g. refcount and usage_count) are checked or changed, a spinlock is used. Two specific examples of spinlock usage are given below:
- The following shows how to pin the buffer descriptor:
- Acquire a spinlock of the buffer descriptor.
- Increase the values of its refcount and usage_count by 1.
- Release the spinlock.
1
2
3
4LockBufHdr(bufferdesc); /* Acquire a spinlock */
bufferdesc->refcont++;
bufferdesc->usage_count++;
UnlockBufHdr(bufferdesc); /* Release the spinlock */
- The following shows how to set the dirty bit to ‘1’:
- Acquire a spinlock of the buffer descriptor.
- Set the dirty bit to ‘1’ using a bitwise operation.
- Release the spinlock.
1
2
3
4
5
6
7
8
9#define BM_DIRTY (1 << 0) /* data needs writing */
#define BM_VALID (1 << 1) /* data is valid */
#define BM_TAG_VALID (1 << 2) /* tag is assigned */
#define BM_IO_IN_PROGRESS (1 << 3) /* read or write in progress */
#define BM_JUST_DIRTIED (1 << 5) /* dirtied since write started */
LockBufHdr(bufferdesc);
bufferdesc->flags |= BM_DIRTY;
UnlockBufHdr(bufferdesc);
Changing other bits is performed in the same manner.
NOTE
In version 9.6, the spinlocks of buffer manager will be replaced to atomic operations. See this result of commitfest. If you want to know the details, refer to this discussion.
How the Buffer Manager Works
This section describes how the buffer manager works. When a backend process wants to access a desired page, it calls the ReadBufferExtended function.
The behavior of the ReadBufferExtended function depends on three logical cases. Each case is described in the following subsections. In addition, the PostgreSQL clock sweep page replacement algorithm is described in the final subsection.
Accessing a Page Stored in the Buffer Pool
First, the simplest case is described, i.e. the desired page is already stored in the buffer pool. In this case, the buffer manager performs the following steps:
- Create the buffer_tag of the desired page (in this example, the buffer_tag is ‘Tag_C’) and compute the hash bucket slot, which contains the associated entry of the created buffer_tag, using the hash function.
- Acquire the BufMappingLock partition that covers the obtained hash bucket slot in shared mode (this lock will be released in step (5)).
- Look up the entry whose tag is ‘Tag_C’ and obtain the buffer_id from the entry. In this example, the buffer_id is 2.
- Pin the buffer descriptor for buffer_id 2, i.e. the refcount and usage_count of the descriptor are increased by 1 ( Section 8.3.2 describes pinning).
- Release the BufMappingLock.
- Access the buffer pool slot with buffer_id 2.
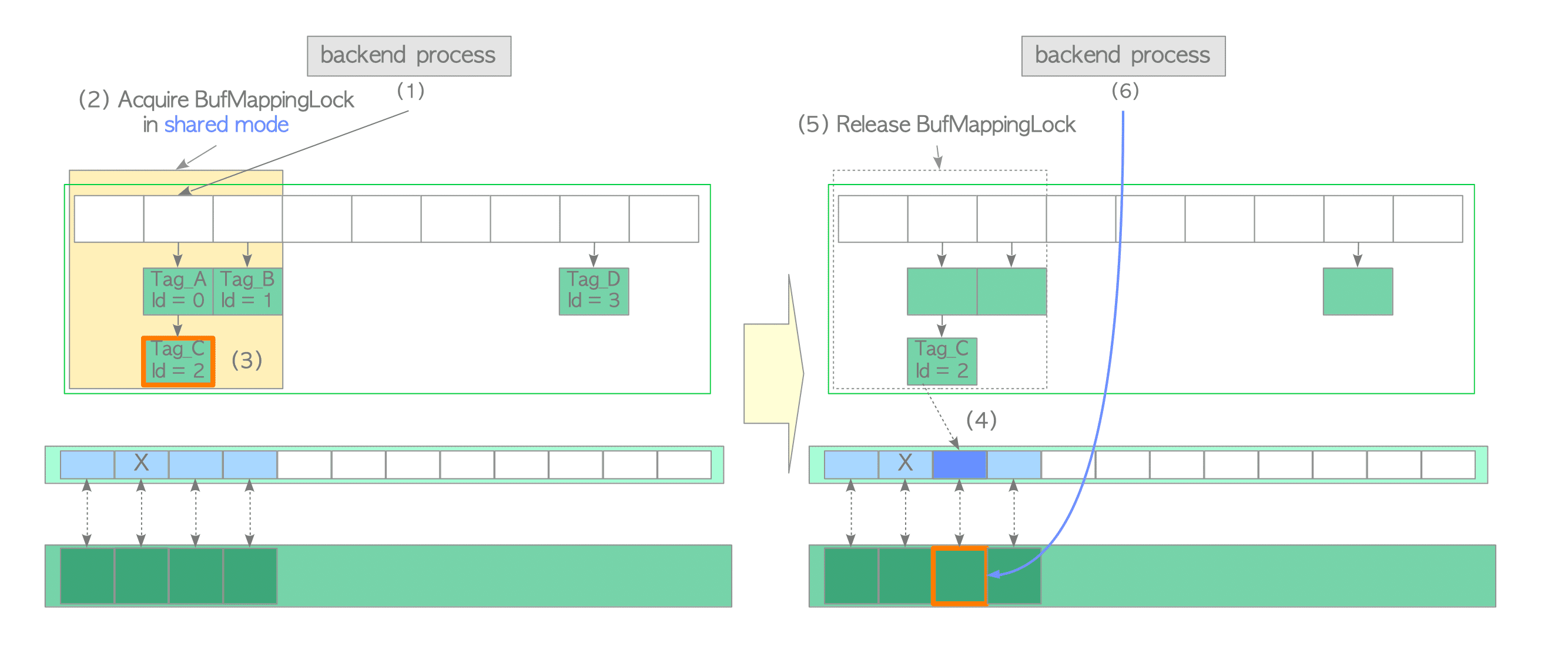
Then, when reading rows from the page in the buffer pool slot, the PostgreSQL process acquires the shared content_lock of the corresponding buffer descriptor. Thus, buffer pool slots can be read by multiple processes simultaneously.
When inserting (and updating or deleting) rows to the page, a Postgres process acquires the exclusive content_lock of the corresponding buffer descriptor (note that the dirty bit of the page must be set to ‘1’).
After accessing the pages, the refcount values of the corresponding buffer descriptors are decreased by 1.
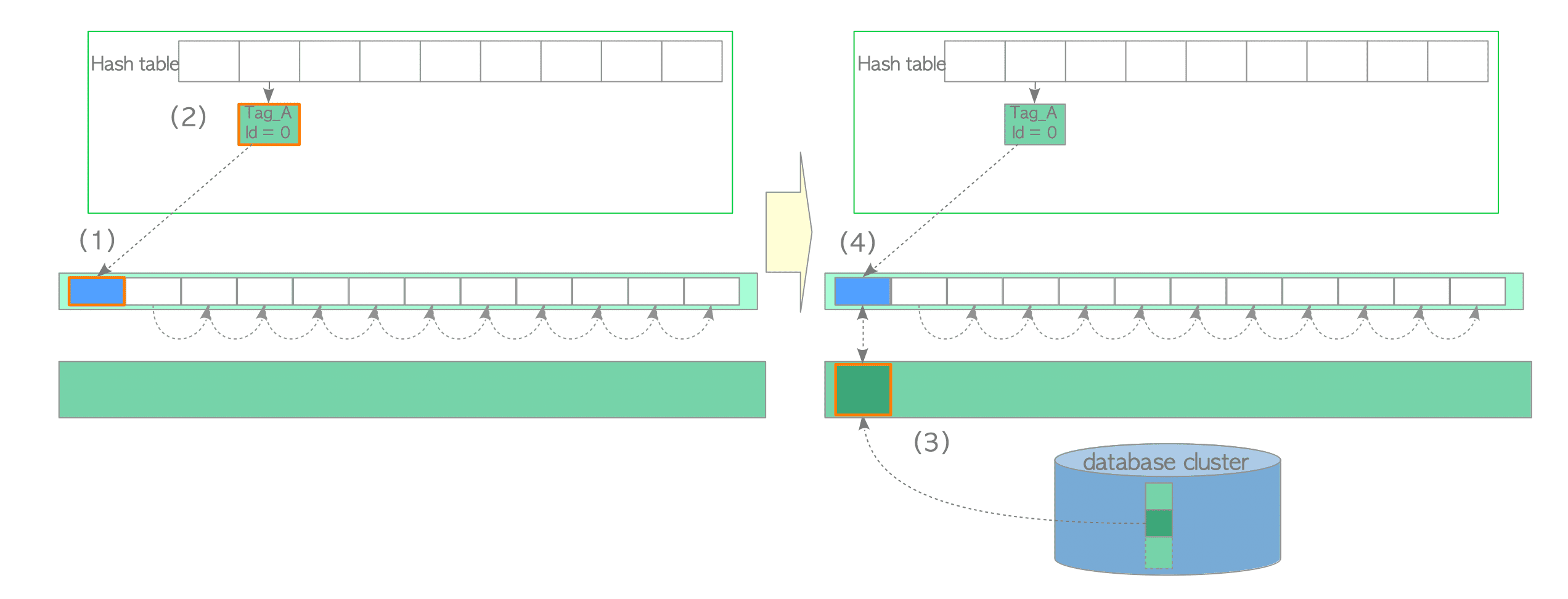
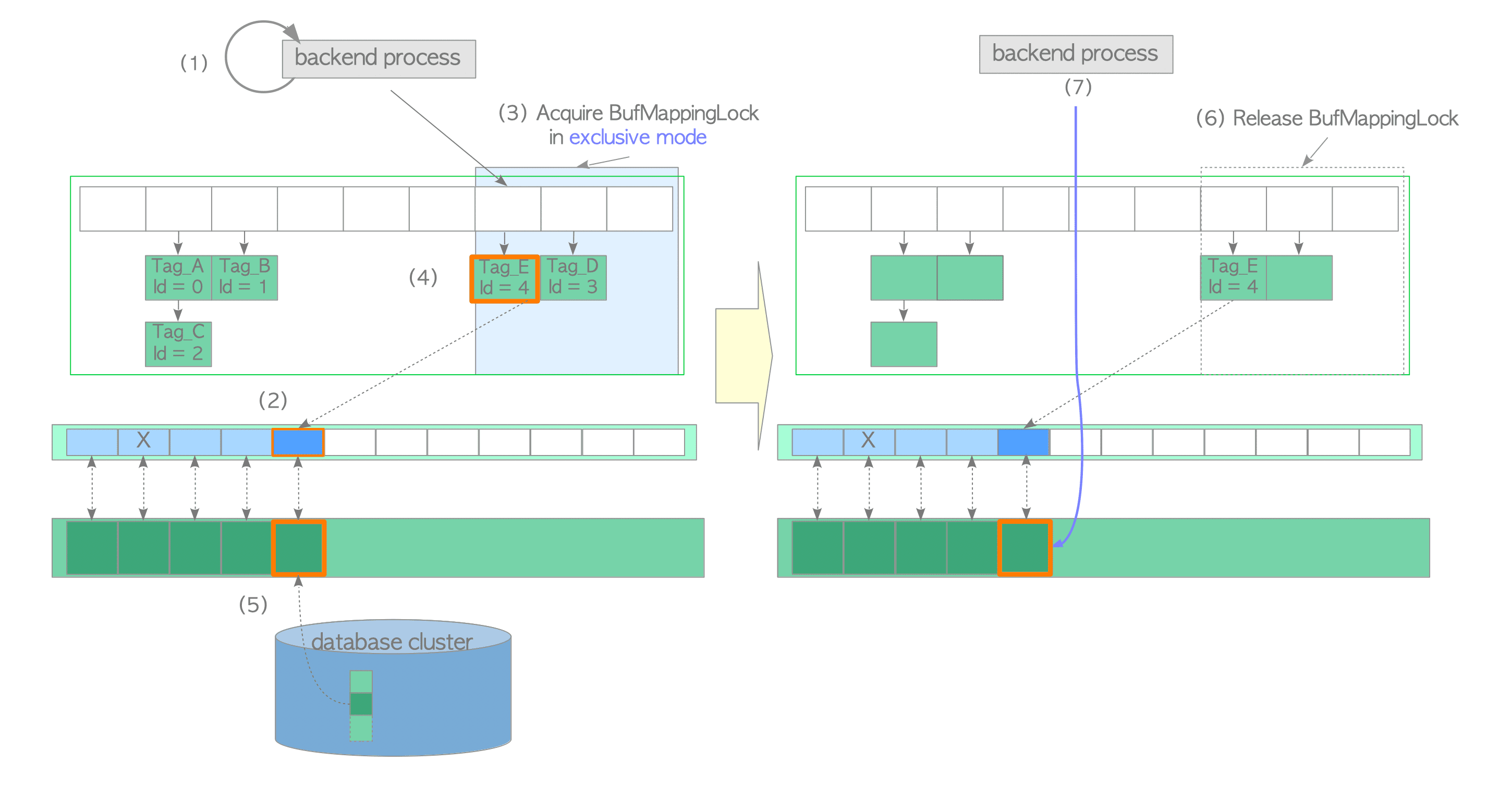
Loading a Page from Storage to Empty Slot
In this second case, assume that the desired page is not in the buffer pool and the freelist has free elements (empty descriptors). In this case, the buffer manager performs the following steps:
- Look up the buffer table (we assume it is not found).
- Create the buffer_tag of the desired page (in this example, the buffer_tag is ‘Tag_E’) and compute the hash bucket slot.
- Acquire the BufMappingLock partition in shared mode.
- Look up the buffer table (not found according to the assumption).
- Release the BufMappingLock.
- Obtain the empty buffer descriptor from the freelist, and pin it. In this example, the buffer_id of the obtained descriptor is 4.
- Acquire the BufMappingLock partition in exclusive mode (this lock will be released in step (6)).
- Create a new data entry that comprises the buffer_tag ‘Tag_E’ and buffer_id 4; insert the created entry to the buffer table.
- Load the desired page data from storage to the buffer pool slot with buffer_id 4 as follows:
- Acquire the exclusive io_in_progress_lock of the corresponding descriptor.
- Set the io_in_progress bit of the corresponding descriptor to ‘1 to prevent access by other processes.
- Load the desired page data from storage to the buffer pool slot.
- Change the states of the corresponding descriptor; the io_in_progress bit is set to ‘0’, and the valid bit is set to ‘1’.
- Release the io_in_progress_lock.
- Release the BufMappingLock.
- Access the buffer pool slot with buffer_id 4.
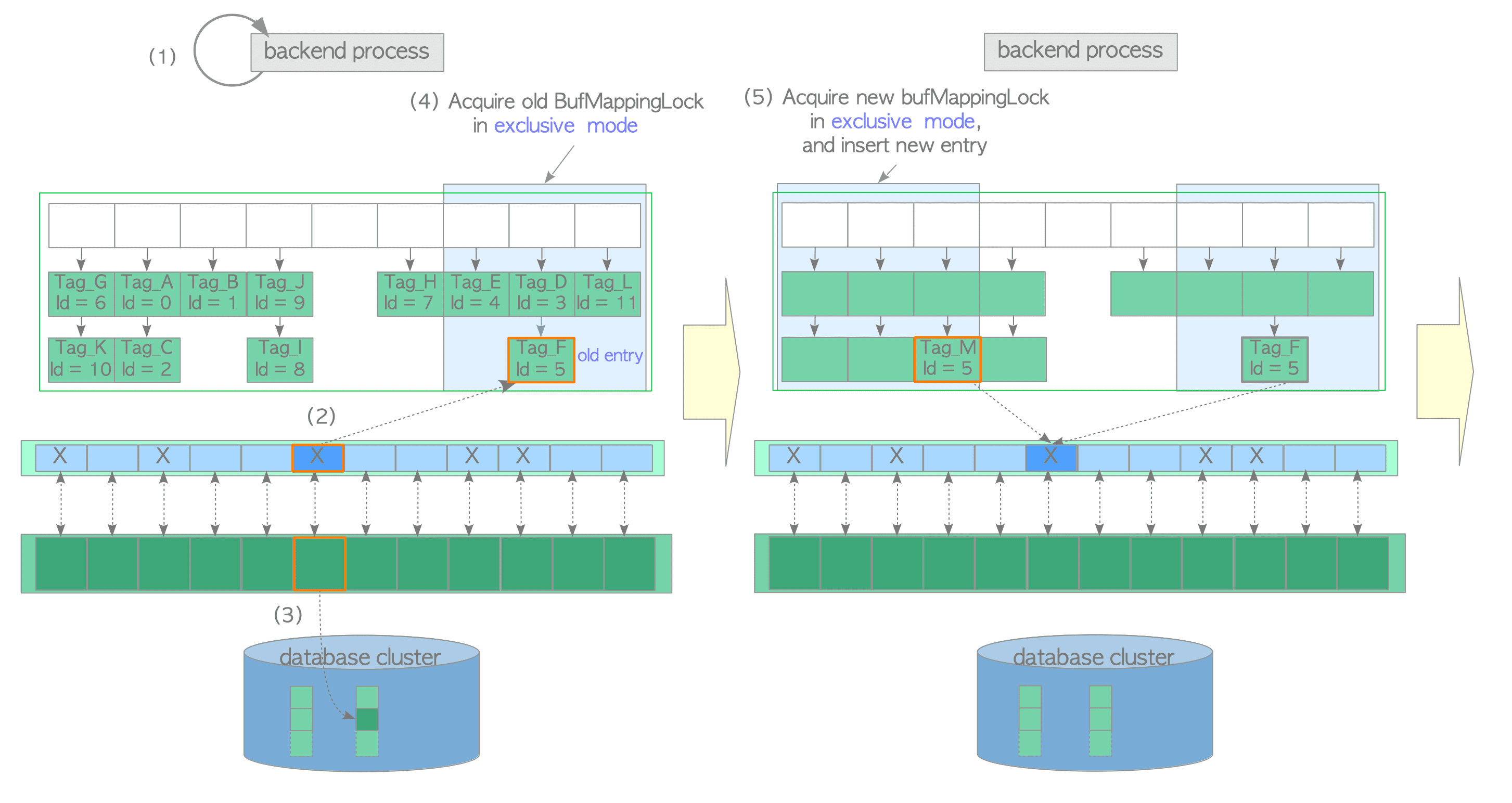
Loading a Page from Storage to a Victim Buffer Pool Slot
In this case, assume that all buffer pool slots are occupied by pages but the desired page is not stored. The buffer manager performs the following steps:
- Create the buffer_tag of the desired page and look up the buffer table. In this example, we assume that the buffer_tag is ‘Tag_M’ (the desired page is not found).
- Select a victim buffer pool slot using the clock-sweep algorithm, obtain the old entry, which contains the buffer_id of the victim pool slot, from the buffer table and pin the victim pool slot in the buffer descriptors layer. In this example, the buffer_id of the victim slot is 5 and the old entry is ‘Tag_F, id=5’. The clock sweep is described in the next subsection.
- Flush (write and fsync) the victim page data if it is dirty; otherwise proceed to step (4).
The dirty page must be written to storage before overwriting with new data. Flushing a dirty page is performed as follows:- Acquire the shared content_lock and the exclusive io_in_progress lock of the descriptor with buffer_id 5 (released in step 6).
- Change the states of the corresponding descriptor; the io_in_progress bit is set to ‘1’ and the just_dirtied bit is set to ‘0’.
- Depending on the situation, the XLogFlush() function is invoked to write WAL data on the WAL buffer to the current WAL segment file (details are omitted; WAL and the XLogFlush function are described in Chapter 9).
- Flush the victim page data to storage.
- Change the states of the corresponding descriptor; the io_in_progress bit is set to ‘0’ and the valid bit is set to ‘1’.
- Release the io_in_progress and content_lock locks.
- Acquire the old BufMappingLock partition that covers the slot that contains the old entry, in exclusive mode.
- Acquire the new BufMappingLock partition and insert the new entry to the buffer table:
- Create the new entry comprised of the new buffer_tag ‘Tag_M’ and the victim’s buffer_id.
- Acquire the new BufMappingLock partition that covers the slot containing the new entry in exclusive mode.
- Insert the new entry to the buffer table.
- Delete the old entry from the buffer table, and release the old BufMappingLock partition.
- Load the desired page data from the storage to the victim buffer slot. Then, update the flags of the descriptor with buffer_id 5; the dirty bit is set to ‘0 and initialize other bits.
- Release the new BufMappingLock partition.
- Access the buffer pool slot with buffer_id 5.
Page Replacement Algorithm: Clock Sweep
The rest of this section describes the clock-sweep algorithm. This algorithm is a variant of NFU (Not Frequently Used) with low overhead; it selects less frequently used pages efficiently.
Imagine buffer descriptors as a circular list (Fig. 8.12). The nextVictimBuffer, an unsigned 32-bit integer, is always pointing to one of the buffer descriptors and rotates clockwise. The pseudocode and description of the algorithm are follows:
Pseudocode: clock-sweep
1
2
3
4
5
6
7
8
9
10
11
12
WHILE true
(1) Obtain the candidate buffer descriptor pointed by the nextVictimBuffer
(2) IF the candidate descriptor is unpinned THEN
(3) IF the candidate descriptor's usage_count == 0 THEN
BREAK WHILE LOOP /* the corresponding slot of this descriptor is victim slot. */
ELSE
Decrease the candidate descriptpor's usage_count by 1
END IF
END IF
(4) Advance nextVictimBuffer to the next one
END WHILE
(5) RETURN buffer_id of the victim
1 | |
A specific example is shown in Fig. 8.12. The buffer descriptors are shown as blue or cyan boxes, and the numbers in the boxes show the usage_count of each descriptor.
Ring Buffer
When reading or writing a huge table, PostgreSQL uses a ring buffer rather than the buffer pool. The ring buffer is a small and temporary buffer area. When any condition listed below is met, a ring buffer is allocated to shared memory:
- Bulk-reading
When a relation whose size exceeds one-quarter of the buffer pool size (shared_buffers/4) is scanned. In this case, the ring buffer size is 256 KB. - Bulk-writing
When the SQL commands listed below are executed. In this case, the ring buffer size is 16 MB.- COPY FROM command.
- CREATE TABLE AS command.
- CREATE MATERIALIZED VIEW or REFRESH MATERIALIZED VIEW command.
- ALTER TABLE command.
- Vacuum-processing
When an autovacuum performs a vacuum processing. In this case, the ring buffer size is 256 KB.
The allocated ring buffer is released immediately after use.
The benefit of the ring buffer is obvious. If a backend process reads a huge table without using a ring buffer, all stored pages in the buffer pool are removed (kicked out); therefore, the cache hit ratio decreases. The ring buffer avoids this issue.
Why the default ring buffer size for bulk-reading and vacuum processing is 256 KB?
Why 256 KB? The answer is explained in the README located under the buffer manager’s source directory.
For sequential scans, a 256 KB ring is used. That’s small enough to fit in L2 cache, which makes transferring pages from OS cache to shared buffer cache efficient. Even less would often be enough, but the ring must be big enough to accommodate all pages in the scan that are pinned concurrently. (snip)
Flushing Dirty Pages
In addition to replacing victim pages, the checkpointer and background writer processes flush dirty pages to storage. Both processes have the same function (flushing dirty pages); however, they have different roles and behaviours.
The checkpointer process writes a checkpoint record to the WAL segment file and flushes dirty pages whenever checkpointing starts. Section 9.7 describes checkpointing and when it begins.
The role of the background writer is to reduce the influence of the intensive writing of checkpointing. The background writer continues to flush dirty pages little by little with minimal impact on database activity. By default, the background writer wakes every 200 msec (defined by bgwriter_delay) and flushes bgwriter_lru_maxpages (the default is 100 pages) at maximum.
为什么要从background writer分离出checkpointer?
在9.1或更早版本中,background writer定期执行checkpoint处理。在版本9.2中,checkpointer进程已与background writer进程分离。在“Separating bgwriter and checkpointer” 提案中描述了原因。
1
2
Currently(in 2011) the bgwriter process performs both background writing, checkpointing and some other duties. This means that we can't perform the final checkpoint fsync without stopping background writing, so there is a negative performance effect from doing both things in one process.
Additionally, our aim in 9.2 is to replace polling loops with latches for power reduction. The complexity of the bgwriter loops is high and it seems unlikely to come up with a clean approach using latches.
1 | |

